


My discussion with Natalie Jackson
Reasonable people can (and should) argue

If you know me, or read my work, you know I'm not shy about being critical of people's work. I'm not a hypocrite in that sense, I welcome criticism of my work as well.
In fact, my philosophy towards any field of science, stats, or generally fact-finding mission is that you must be open to criticism.
Unfortunately, in the social media era (where uninformed opinions demand the same standing as informed facts) it's entirely understandable why experts would ignore or disregard the critical commentary of randos.
In terms of credentials in this field, I'm not far above “rando.”
I believe (and know) my work stands on its merits, and while it's an uphill battle to make an impact, in the end better data and models win.
Reasonable people can argue, but only unreasonable people would think that more or better credentials shields them from criticism or being wrong.
Being open to criticism doesn't mean engaging with every person who spouts a disagreement. So I suppose I should clarify, being a good analyst or good scientist means being open to reasonable criticism.
For that reason, I gained a good amount of respect for Jackson through this interaction for the fact that she engaged - even if it didn't make much of a difference in the end.
I'll share the conversation here in a more user-friendly format than the original X convo.
My first post is in response to a comment discussing reputability of various forecasters.
It starts with a vital (and needed) note about the current state of the field: there is zero accountability.

It's bad enough to publish a model/forecast that is terrible. It is worse, in my opinion, to publish that bad forecast and take zero accountability.
In 2022, my first Senate forecast - released long before any other forecaster - included a Texas race that didn't exist. Oops.
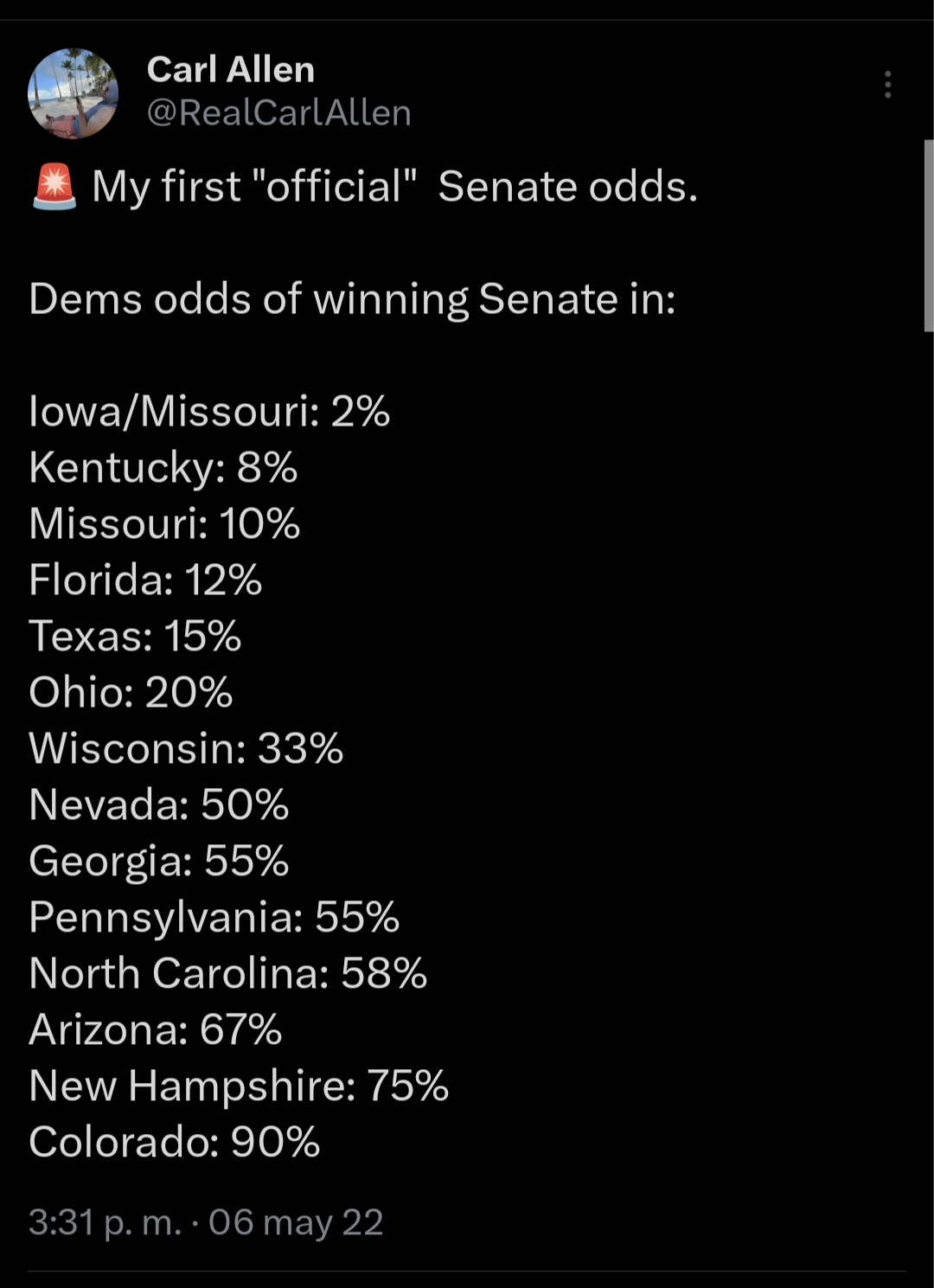
I took a lot of shit for that. It's fine! I messed up. My gubernatorial stuff leached into my Senate stuff - but it doesn't matter. I messed up, I admitted it. If memory serves, I didn't even make an excuse (which happened to be a relatively valid reason) as to why it happened. I just said I was wrong, and fixed it. Weird!
And for the record - a full month before any other forecaster released anything - a forecast for which I was absolutely flamed by daring to say Dems would be favored in midterms looked like this:

Those odds were very much to the left of the betting markets, and the not insignificant observation (or, more aptly put, forecast) that Oz would be a weaker candidate for Rs than the alternatives proved extremely accurate, I think.
Unfortunately what happens in the forecasting & poll analysis field right now is the opposite of accountability. In (hilariously accurate) meme form, that might look something like this:

Treating poll margin as predictive is as silly as using a gubernatorial forecast as a Senate forecast. But only one of them are understood as wrong.
Which leads me to Natalie's response to my criticism of her/Huffington Post’s “Hillary 98% to win” forecast, and a call for accountability.

This starts off pretty strong, honestly. I respect the “Google it” approach and I'm not being sarcastic. I don't expect or even want people who have written extensively on a topic to restate it for social media.
One big problem. The hedgiest hedge possible.

“The underlying problem was indeed the poll data”
So close!
This shirking of accountability, blaming “the polls,” is unfortunately the standard for forecasters and analysts in this field, and a terrible standard I hope to help correct.
More to the central point about the lack of statistical literacy in this field (credentialed or otherwise) comes from the first sentence.
“There were 0 polls showing Clinton losing Wisconsin or Michigan..”
My response to anyone who says this - I don't care if you have a PhD or have never studied this in your life:
Not a single poll in the history of ever has ever “showed” anyone winning anything.
This is bluntly and, I might add, indisputably true, based on a very basic understanding of how polls work.
Not understanding how polls work and simultaneously blaming them for your bad forecasts is really indicative of a field without direction.
My response to this comment of hers is as direct as her “Google it” comment was to me. Because that's what it deserved.
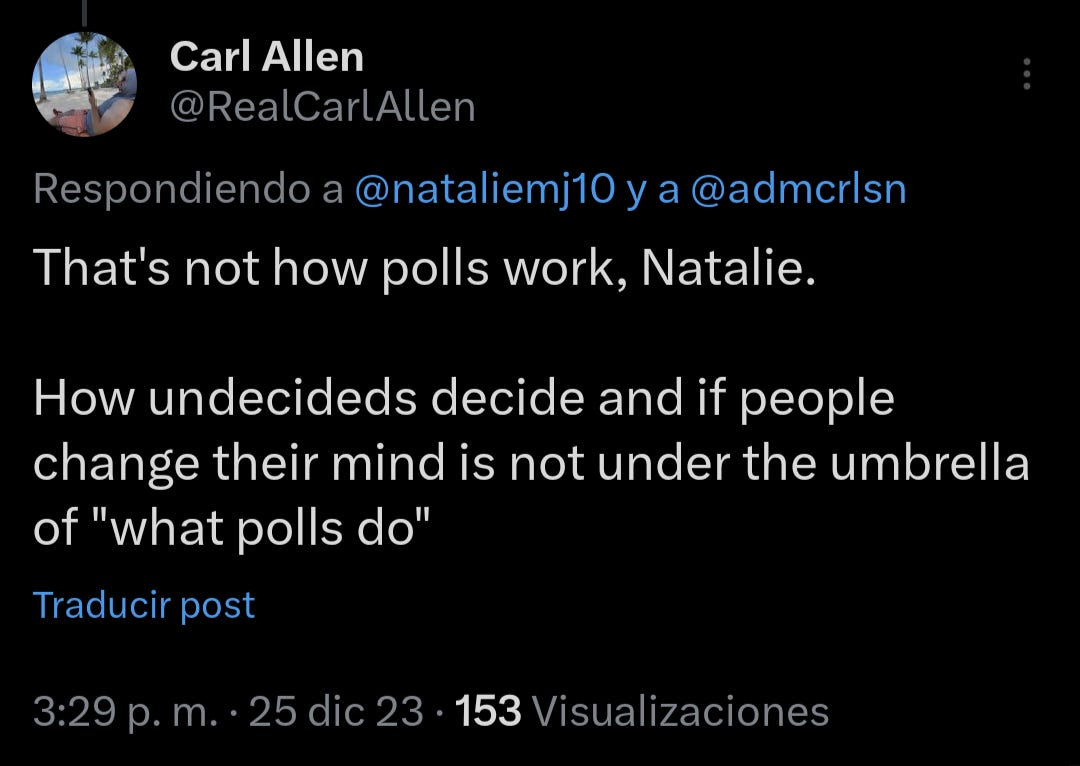
Despite demonstrating that she doesn't know how polls work - a common but brutal misconception that is plaguing this field and the public - she wants me to to read other stuff she's written.
This is a deflection.
I know (because I actually have read lots of her analysis!) that she's not a hack like Wang and others. But how much work of hers I've read is irrelevant if her understanding of polls is poor.

Having read extended pieces she's written on polls is irrelevant when there's such a fundamental misunderstanding to be addressed.
But she does circle back to the key point here:
“We shouldn't be doing this with polls.”
Awesome. Love it. I want to clarify what she means, because if I understand correctly then it means we agree.

“We…shouldn't be treating polls like predictions”
We agree! So why are we arguing?
Because of that circular reasoning that has poisoned the mind of the public, analysts, and experts alike:
We know polls are intended to be snapshots, not predictions…but we judge their accuracy by how well they predict the result?
As I said above: that doesn't math.
In other words (something I wrote elsewhere):

Since I'm a terrible writer, I'll be making the most important piece of this conversation - one that is central to fixing the foundations of poll analysis and forecasting fields - before sharing the rest of the convo.

Here again, Jackson refers to the “no polls showing Trump winning” fallacy again, not 2 minutes after acknowledging that polls aren't intended to be predictive.
The line
“You cannot make up data inputs that show Trump winning in a forecast that you say is based on polls as data inputs.”
Is the most crucial line in this conversation.
It gets to the absolute core of the difference between polls and forecasts, and why blaming polls for a bad forecast is not just shirking accountability, it's a denigration of science and population statistics as a whole.
A poll showing Clinton “ahead” ~44-40 (as in my example) or ~46-43 (as she was in her most promising swing states) means, in academic terms, jack-f**king-nothing for win probability.
Nothing.
Why?
Because there are a lot of undecided voters.
And what do polls tell us about the eventual preferences of undecided voters?
Nothing.
That's the job of a forecast.
Modeling a range of possible outcomes doesn't require making anything up. It requires modeling.
Namely, how undecideds will eventually decide, and voters who might change their mind.
“How likely is it that Clinton loses with a ~4 point lead?” Is the question forecasters who should quit forever asked themselves.
“How likely is it that Clinton loses with a ~4 point lead given 8-12% undecided?” is much closer to the right question.
In order to calculate that probability, you need a model, and forecast.
And I don't care where you went to school or what degrees you have, that number is much higher than 2%.
The belief that it is highly unlikely for Trump to win simply because he is not “ahead” in many/any polls (and that you have to make anything up to model uncertain probabilistic outcomes) is very misplaced. Well, it's wrong.
She did not respond to that tweet. The convo continued on a different post.

I agree: it does take a lot of chutzpah to tell someone with lots of experience that they're wrong.
But you know what?
It takes a lot more chutzpah to claim your credentials or experience preclude you from being wrong, especially when in every post the claim that you're wrong is supported with specific reasoning.
It seems debates of facts won't be settled by chutzpah. Nor will they be settled by a credential-measuring contest.
They'll be settled by facts. Well, I hope; it's not up to me.

Again asserting that a forecast giving Trump a reasonable chance of winning would require making numbers up?
I'll be honest. I like Natalie, certainly more than a lot of other people in this field.
But there's no nice way to say that this is the kind of misunderstanding that demonstrates a lack of basic statistical literacy.
If you want to dismiss it as “condescending,” fine. I'll Google what condescending means then let you know how I feel about it.
But it's not wrong.
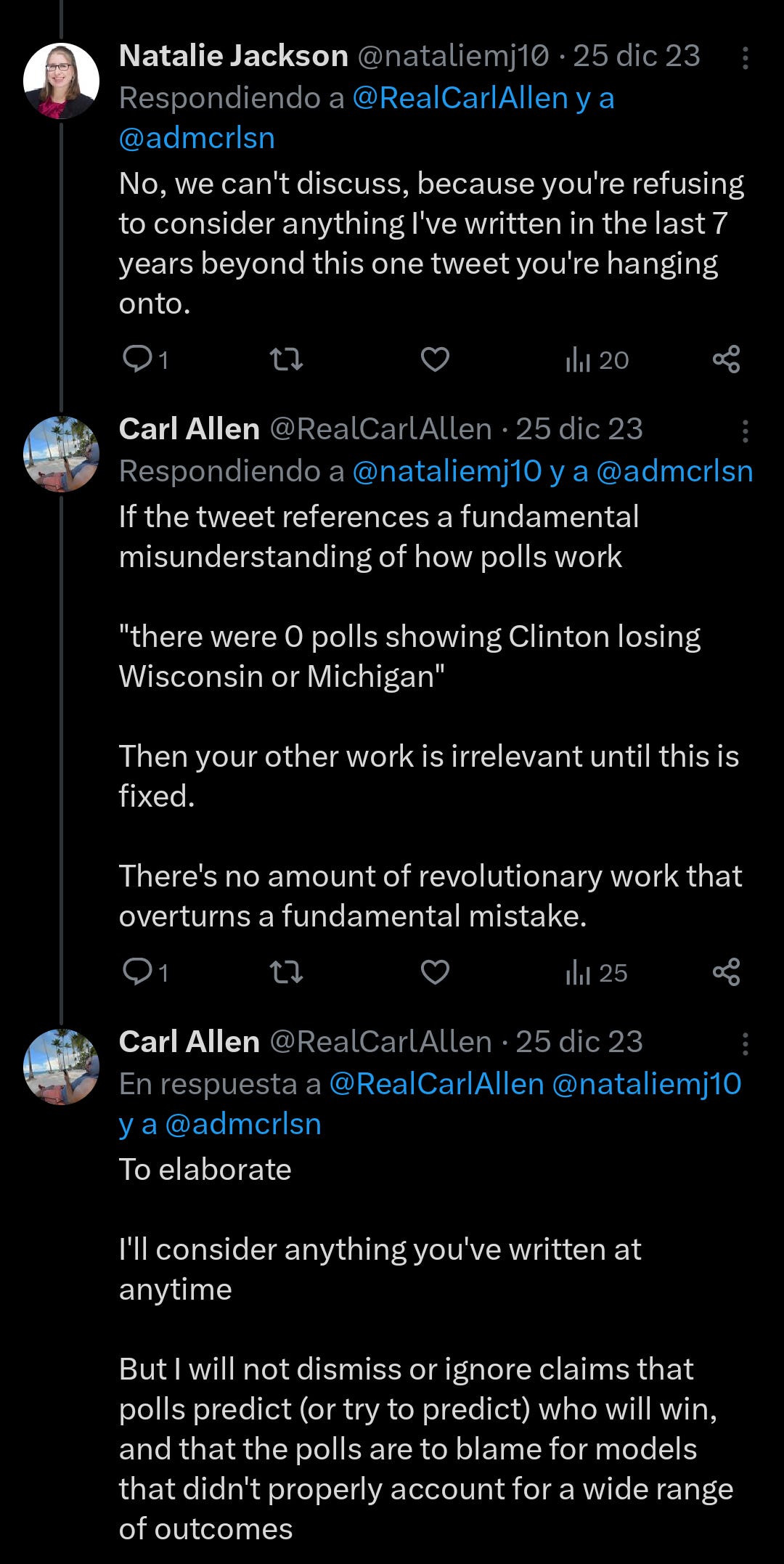
There is no amount of revolutionary work that overturns a fundamental mistake.
Jackson has and will contribute a great deal to the field. But that doesn't erase being wrong about something else.
It's not Jackson. It's not Silver. It's not (insert random social media user here). It's everyone. It's a problem when the average person does it, but it's devastating when perceived experts reinforce that wrongness.
Hence, my call for accountability.
As usual, there's a timestamp. Here's a post I made a week prior to this discussion.

It doesn't matter what their credentials are if they're wrong.

It's not personal. Being wrong is not indicative of the quality of your work, but refusing to admit it is.

This is where it ended - not including a few very not-condescending tone posts from her telling me to “go away.”
So what do you think?
Was I too mean, short, or unfair?
Or am I correct in my perception that this field is in need of some major overhauls?
Let me know what you think.