

Sometimes, if you're debating someone, they'll say “oh you're just arguing semantics.”
As if this were some magical way to dismiss your argument.
True, quibbling about the meaning of words is sometimes a distraction.
This is not true in science.

You'll note I asked a direct question of central relevance in response to his original post in this thread, to which he responded with 5 sentences entirely unrelated.
I suspect Tom wouldn't be so dismissive of properly defining the term “error” or “accuracy” if it were a topic he understood better.
For example, the difference between confidence intervals and credible intervals. Nerd stuff. No person educated on the topic would argue they were the same.
So if I (to prove a point) intentionally confuse the two, might Tom correct me?
To use a simpler example, how about if I said registered voters and likely voters are “basically the same”? (They are, btw)
Bet money he'd correct me. Because that narrow difference, in his mind, matters - and he understands it.
And you know what the substance of that debate would be?
Semantics.
The definition of words.
People like Tom (who isn't alone, in the slightest) think calling something “semantics” is the same as saying something “doesn't matter.”
No expert in the field would conclude the difference between registered voters vs likely voters doesn't matter.
So why do experts with terms like “poll error” and “poll accuracy”?
They either don't understand what they're talking about, they aren't aware of the ramifications of not understanding them, or they don't care. There's no other explanation.
Except in the case of properly defining “poll error” compared to “likely vs registered voters” the, well, error is larger.
Believe it or not
The reason I like to argue with people on the Internet is not because I like to argue with people on the Internet. Nor is it because I think I'm particularly smart: how smart I am makes no difference to how right I am.
“Okay, you're smarter and more experienced than me…care to address my actual arguments now?”
*Silence*
Arguing with people teaches me weaknesses of my position, how to make my points more concisely, stay on topic, make sure I force them to stay on topic, and say things in a way that can't be misunderstood.
So when it comes to poll data, let me explain at a level anyone can understand.
Current calculations for poll accuracy make two assumptions:
1) People don't change their mind within ~3 weeks of an election
2) Undecideds split evenly (US analysts) undecideds split proportionally to decideds (non-US analysts)
Both 1 and 2 are testable.
Both 1 and 2 are always wrong.
This is not debatable.
At this point, the argument quickly changes to “but…negligible…but…”
No. How negligible they are, if they're negligible at all, is a separate topic.
Topic 1 is: are the assumptions made in “1” and “2” always true?
The answer is no.
In fact, they are NEVER true.
Only after that basic fact has been established is there any debate to be had about the magnitude of error in those assumptions.
Anyone who claimed registered voters and likely voters can be assumed as “the same” because they sometimes, maybe, kind of, are “pretty close” would not be entertained by any expert.
For the same reason:
I will not entertain any debate with anyone who doesn't admit what is observed to be true.
“1” and “2” are false.
Once this is settled,
The debate is:
1) How wrong are these assumptions?
2) Can we/must we do better?
Answers I've found:
1) Anywhere from tiny to enormous
In elections with very few undecideds/third-parties, the assumptions above (while imprecise) are "okay"
A hypothetical two-way election with a poll average of 50-47 (3% undecided)
In which the undecideds split 2% for the leader, 1% for the other, would end up 52-48.
This is a pretty large split (66% of undecideds) but the “spread” error assigned to this poll is only 1%. It's not nothing, but it would take a drastic case for the assumptions to fail catastrophically.
You'll note, elections with very few third-parties and undecideds (e.g. 2008 and 2012) have very small “error” according to these methods. It turns out, making bad assumptions works out okay if those assumptions aren't tested.
But in elections that don't fit that - vast majority of them - the amount of "error" assigned to polls can easily be DOUBLE the true error.
Take the example of the 2016 Trump-Clinton election.
We know undecideds were higher than usual, and split heavily for Trump.

We know third-parties were higher than usual, and changed their mind heavily for Trump.
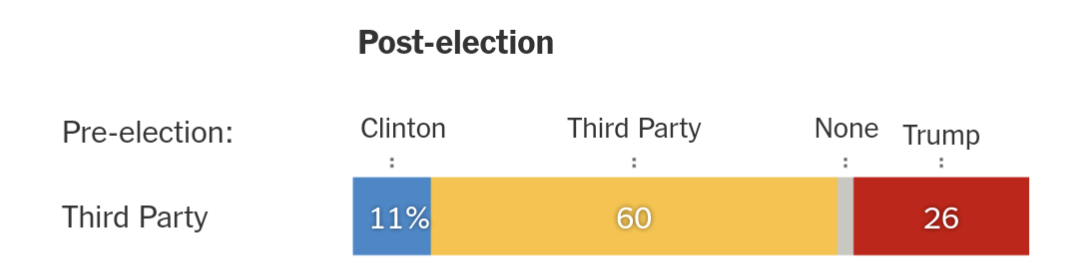
But current methods assume people polled as“third party” voters should vote 100% third-party in the election (that is, zero mind-changing)
And “undecided” voters should split evenly.
So knowing this, the brilliant analysts at 538 (who were smart enough to do the hard work of obtaining the data) certainly incorporated it into their “poll accuracy” calculations…right?
Nooooope.
To this day, starting with the day after the election, FiveThirtyEight calculated the “error” of the polls with the assumptions they knew were wrong.

And everyone else, following their statistically invalid metrics, does the same.

Not accounting for confounding variables is, by definition, bad science. Semantics.
By these methods, “mind-changing” and “50/50 undecided” split are confounding variables that impact the “poll-to-election” number they call “poll error.”
It's not just semantics either. They say the polls were “wrong” and need “fixed” largely because their assumptions were wrong.
So to address “2” above
2) Yes
For those who want to see some simple math, that experts are incapable of doing by their own admission:
The amount of error in the following:
45% Candidate A
42% Candidate B
8% Candidate C-E
5% Undecided
Current methods say “unless candidate A wins by 3, poll wuz wrong”
This is what passes for math among experts, I guess.
Well, let's plug in some knowns from 2016:
Undecideds split 60-30 in favor of Candidate B (10% for Candidates C-E).
That “undecided” adjustment means the eventual result (with no error) would be
Candidate A: 46.5%
Candidate B: 45%
Candidate C-E 8.5%
But we're not done yet.
We also know Candidates C-E underperformed their numbers (only 60% went to them)
Candidate C-E now at 5.1%
Where did the rest go?
30% to Candidate B
10% to Candidate A
Now, with the third-party mind-changing adjustment, a poll with zero (predictive) error, zero compensating error, stuff that is totally just semantics, would have produced an eventual result of:
Candidate A: 47.3%
Candidate B: 47.5%
Candidate C-E: 5.1%
Here, simply accounting for known variables, it can be easily shown how a poll/poll average with very little error (e.g. showing Candidate B as “behind” but eventually winning) can be said to have 4 or 5 points of “error” when it has almost none.
That is to say, the method itself attributes more error to the poll (3.2 points, in this case) than the poll itself had (an additional 1-2, in most cases).
Semantics. Math.