
A quick poll math lesson
No, that's not what the "margin of error" is

In math, it's okay to start simple. You have to do arithmetic before attempting algebra.
Being good at arithmetic isn't a guarantee you'll be good at algebra, but it's a pretty necessary prerequisite.
Poll data is not much different.
There are lots of factors that can cause a poll to be wrong (this excellent visual from the AAPOR conference, presented by Pew Research’s Courtney Kennedy, photo from Brady West) demonstrates it:

Currently, the margin of error (sampling error) is the only number reported with polls - but there are lots more contributors, possible and actual.
This is excellent work.
What is not excellent work, however, is comparing polls to elections apples-to-apples and asserting the entirety of the observed discrepancy (how well the poll predicts the election result) is an error.
Here, FiveThirtyEight's Nathaniel Rakich (in the same session, I'm jealous) makes one very good observation: “margin of error only captures a fraction of potential error in polls.”
Agreed. I'm glad there's a discussion about doing better.

Then, he makes a much worse statement: “the *true* margin of error is about twice as high for election polls.”
This is false.
His assertion, the math performed to arrive at this “twice as high” claim, is based in that same, erroneous definition - the one that assumes polls should predict elections.
I'm told I need to be nicer, so I'm trying!
It's not a dig at Nathaniel (or the Nate he used to work for) it is the UNANIMOUS definition used within the field, and it needs fixed. The other Nate said the same thing verbatim 6 years ago, which is what I suspect Nathaniel is citing.
In case you're new to my page (or living under a rock) here's the summarized “poll error” definition used by US analysts:
The percentage difference between the top two candidates in the poll, versus the percentage difference between the top two candidates in the election, equals the poll’s error. This definition is also used with poll averages, as a measure of how wrong “the polls” (plural) were.
Through basic arithmetic, you can easily calculate that this method assumes that even if a poll or poll average were perfect, undecideds must split evenly.
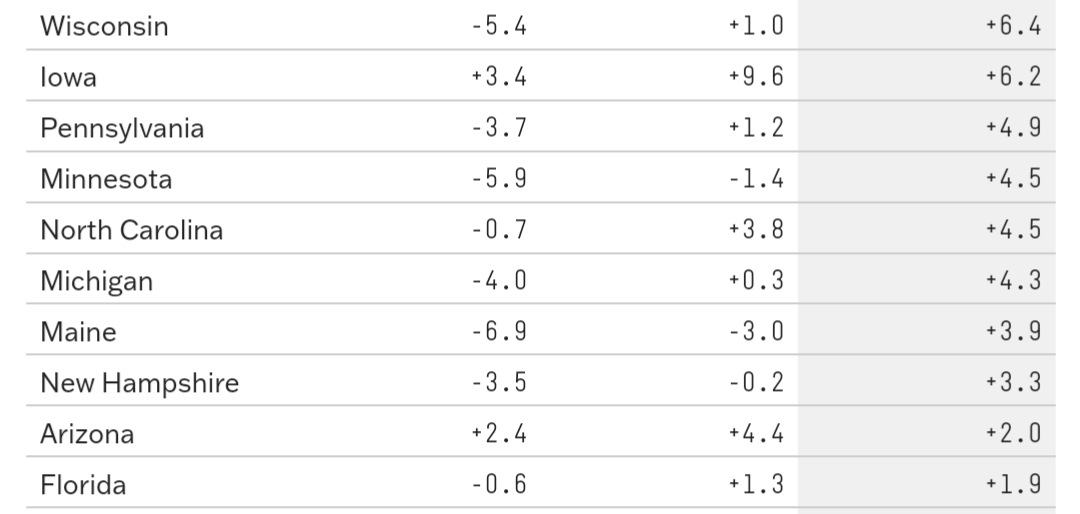
To use Pennsylvania as an example, the poll average used by 538 said Clinton was ahead by 3.7 (46.5 to 42.8).
The eventual result saw Clinton lose PA 47.5 to 48.2. (the numbers 538 reported in the table above were after the election was called, but before votes all counted)
Nonetheless, the entirety of this 4.4 point “error” is attributed to the polls, and the polls alone. The pollsters, FiveThirtyEight says, need to fix their methods.
It's bad math, bad science, and needs to stop.
My background is science. It's a shortcoming of mine to view things strictly from a scientific perspective (what is closer to the truth?) than from a humanistic one (how can I convince people this is correct?).
To my dismay, fixing bad science isn't as easy as showing your work.
But where this all intersects is the impact it has on pollsters.
Due to the flawed methods used by ANALYSTS (not pollsters) even pollsters who do very good work are questioning their work (like Monmouth), and some (like Gallup) were forced out entirely.

To be clear, experts and analysts do a lot of good and important work. Much of that work, I would be unqualified to do and largely incapable of doing.
But this problem of viewing polls as predictions needs fixed long before we talk about or even think about any more technical applications, and I'm very qualified and capable of talking about it and fixing it.
Here's why we need to fix it:
A standard US election has high single-digit undecided. Let's call it 8%. Some higher, some lower.
A close election in this case would have the main candidates at around 46%.
Polls are not perfect. For now, for the sake of math, let's assume this one is and the population the poll attempted to estimate is truly 46-46-8.
A mild undecided split of that 8% - 5 to 3 for either candidate - would yield a final result of 51-49, and thus 2 points of "error" (according to the current, flawed definition).
Where did that error come from?
It came entirely from not predicting what undecideds would do. It's logically absurd to assert that a poll should do that - yet the uncontested definition used in the field says polls should do exactly that.
The proper scientific terminology is “internally invalid” but I prefer appealing to the logic here.
Now, a 2-point "error" is not a lot by current standards, but remember - that 2 point error is not real. The flawed assumptions of the definition - that assumed undecideds must split 50/50 - was the only error.
2 points might seem insignificant, but by the nature of being nearly undetectable, and with zero accountability for their flawed assumptions, this 2 point ASSUMPTION ERROR is piled onto whatever real poll error there may have been.

You'll note, nowhere in here does this presenter say “wrongly assumed what undecideds would eventually do” as a source of error. Because it's not.
Everyone, kind of, knows this - but when it comes time to do election math - they either forget, don't care, or my working hypothesis: them don't understand it.
Every poll ever conducted has some error, likewise for any poll average. Given the number of factors that can contribute to them, any poll that has “zero error” (by any metric) was almost certainly achieved by luck. This gets into compensating error, an important topic which I will discuss in my book, but a little off topic here.
Suffice it to say: If an unexceptional 63/37 split of a mild number of 8% undecided can contribute 2 points of error, and 2 points is not considered a significant error, remember it only takes another 2 to 3 points of actual error for analysts to assert that the polls “missed” or even “failed.”

They missed, as cited in the tables from this article’s analysis, not because of any actual sources of error (see the Pew Research Presentation) - but because they didn't predict the result.
Instead of assuming error is unknown and figuring out what caused the discrepancy between poll and result, these analysts (through arrogance or ignorance) assume their 50/50 undecided split assumption can't be wrong, and that they know how much error there was.
That non-existent two point error caused by uneven undecideds is “no big deal” when polls are otherwise very accurate.
But what happens when
*Gasp*
Polls are a little inaccurate?
Now assume the poll (or poll average) from earlier was not perfect.
The poll(s) are STATED as 46-46-8, but the population it was trying to estimate was actually 47-45-8.
This is, by all accounts, a one point error for each major candidate. Miniscule.
Now, let's apply the same undecided split as before, from this population of 47-45.
Plus 5 for one candidate (now 52) and plus 3 for the other (now 48).
The 46-46 poll was taken in an election where the result was 52-48.
4 point error. Where did it come from?
The 46-46-8 poll report made that enormous, unacceptable, terrible estimate of a population that was truly 47-45-8.
Then those 8% undecideds split such that the result was 52-48.
The entirety of that 4-point “error” is assigned to the pollster by the experts who then tell the media, who then report to the public, that the polls were “wrong” and “missed” and “failed.”
Not just missed and failed, but by the exact amount they say it did.
(Please don't check our work, we are very smart)
And when presented with good evidence that this undecided split caused a good portion of their asserted “error” - do those experts tell the media to tell the public, “hey, we were wrong about how wrong the polls were.”

Lol no. Admit they were wrong? Absolutely not.
It's all the polls' fault, and the bad pollsters should fix their work. It's a pretty sweet gig, honestly. If you forecast the election result right, you get all the credit - and if you're wrong, the pollsters take the blame?
The pressure in this field goes in one direction: on the pollsters. It's not that I'm on anyone's “side” here, but I am not inclined to be friendly to unaccountable quants who do very bad math, are unwilling to correct it, and that math causes good and talented people who do valuable work to question it, quit their job, and those “quants” get promoted with no ramifications for their shoddy work.
Now look at the problem another way, as I briefly introduce compensating errors as they relate to polls
Now, assume a pollster reported 47-45 with 8% undecided, but the actual population is 46-46 with 8% undecided.
The basis for the current poll accuracy calculations, remember, is the “spread” or “margin” in the report.
The basis by which this pollster will be judged is by how close the result is to “+2” (even though, for demonstration, we know the population is +0)
Same undecided splits: 5 to 3.
But remember, the undecideds didn't split from the POLL (estimated) population, it split from the ACTUAL population, which we know was 46-46.
That makes the eventual result 51-49.
Despite this poll having an error, current methods would report it as perfect.
The undecided ratio has “masked” or “compensated” for their reported number’s error.
This poll had a small error, and it is reported as more accurate than it is - not that big of a deal, right?
Wrong.
A poll or poll average taken from a population of 46-46 would do EXCELLENT to obtain an estimate of 47-45. Excellent. Superb.
You don't know where I'm going with this, do you?
A poll would be equally as excellent and superb to obtain an estimate of 45-47, or “-2.”
Now, I think you see where I'm going, but you might not understand what it means.
A poll of 47-45 from a population of 46-46, compared to a poll of 45-47 from the same population, is literally chance. It's luck. Both are objectively outstanding, remarkably accurate.
But what happens if these competing pollsters who, based on the population they estimated, reported these equally accurate results, and were measured by the current standards?
Poll 1
47-45 (+2) poll
51-49 (+2) election = 0 point error
Poll 2
45-47 (-2) poll
51-49 (+2) election = 4 point error
A 4 point “error” discrepancy, for objectively equally good polls, based in junk math.
And remember, a one-point error for each major party is immaculate, but would still arrive at very different error calculations, because one (by pure chance) predicted the result better.
Realistically, competing pollsters could each be off by two or three points, and those are still very good polls - properly measured. But according to current standards, only the one whose error went in the right direction was good.
And now consider what happens to these calculations when we add the fact that people change their minds way more often than you think (current methods assume 0 mind-changing within 3 weeks of election) and the fact that non-US elections often have far more undecideds (and don't report them).
Guys, this is junk science, and it needs fixed.
It's not a hard fix, but we can't start on the hard stuff until people in the field do the easy math and admit it needs to be.
I've noticed that it's common in predictive or analytical discussions to simply never state key assumptions (like how one thinks undecideds will split, which are often implicitly assumed to split in a particular way by an author/op-ed). In macroeconomic analysis it is also common (especially in the recent inflation discussion).
@Lorenzo Warby