

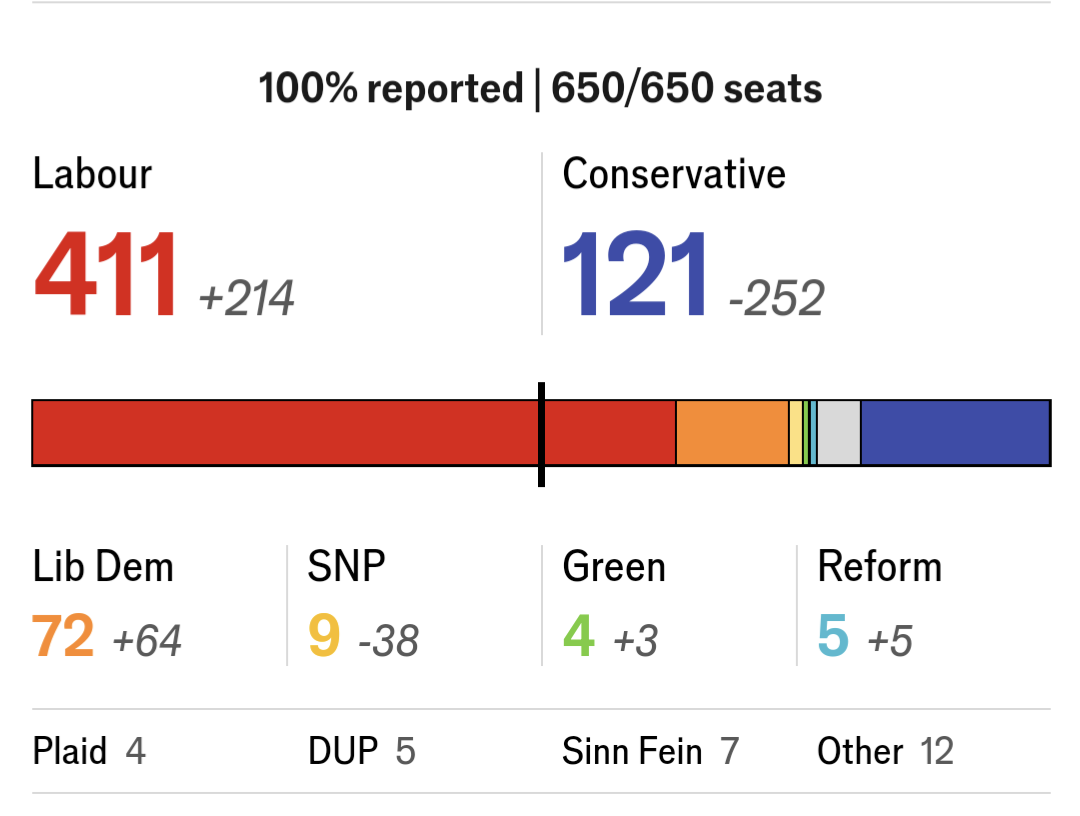
Big Conservative L in UK

Unlike the US, where results sometimes take weeks to count, each UK Constituency - 650 of them - gets the counting done in a few hours.
In close elections, with 326 seats needed for a majority, it can be suspenseful to see if anyone gets to a majority - and even who wins the most seats.
This election was not close.
The campaign cry of the Conservatives was “stop Labour from getting a supermajority”
Their situation was that dire, and it didn't get better on election night.
Blowout. Unlike in the US where we have a 2 month “lame duck” period, the Conservative Prime Minister has already resigned, packed his shit, and left.
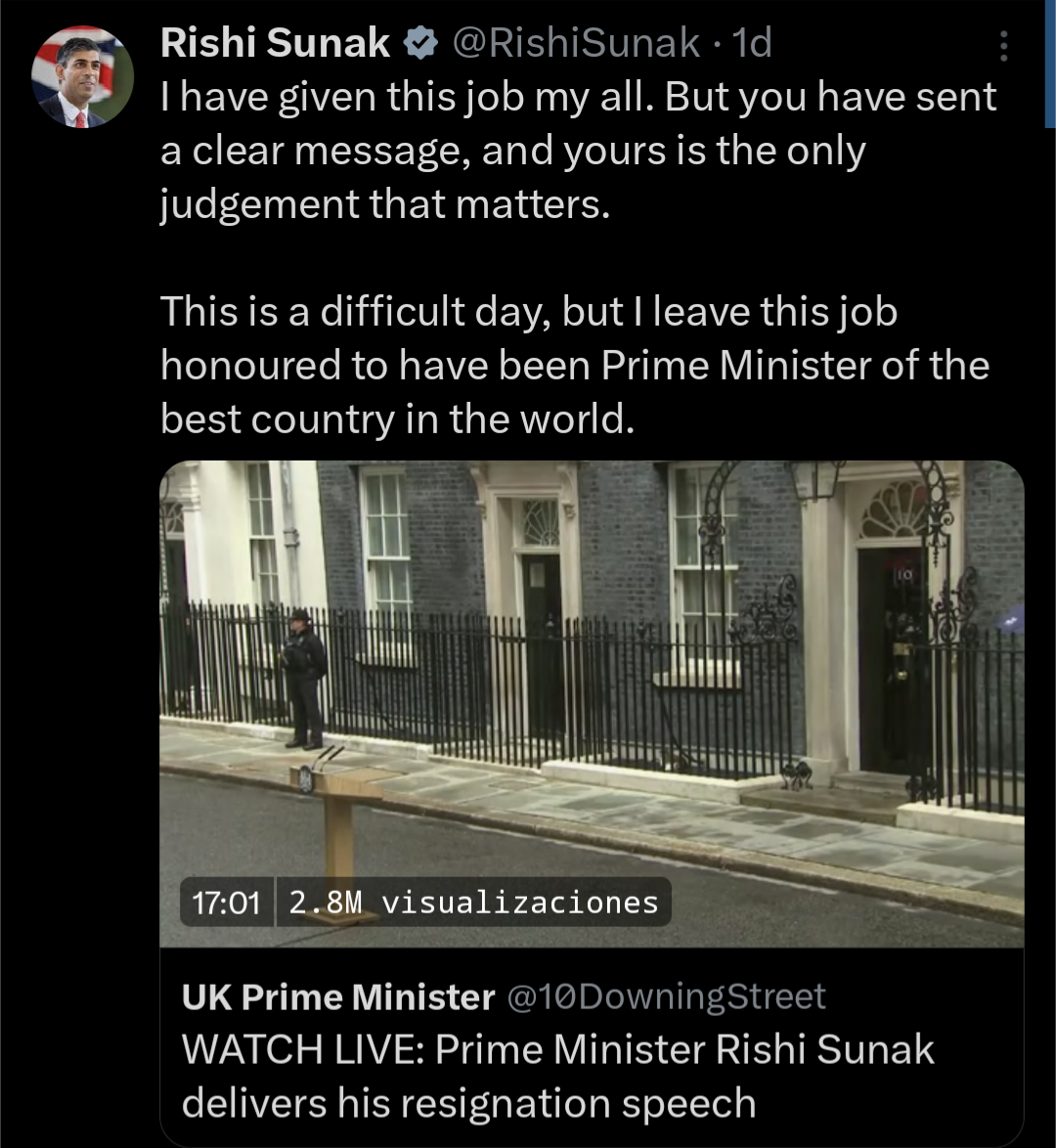
Election on the 4th, gone on the 5th. No 6th.
Sad that we're in a state where a loser conceding with grace is commendable, but here we are.
While the Labour blowout was not unexpected, there were some things that were. And not all forecasts performed well.
Selfishly, here's my seat forecast with the results.
Liberal Democrats hit the higher end of seats I believed they could win without venturing into “unexpected” (around 83rd percentile) while Conservatives and Labour were firmly within my forecast’s middle range.
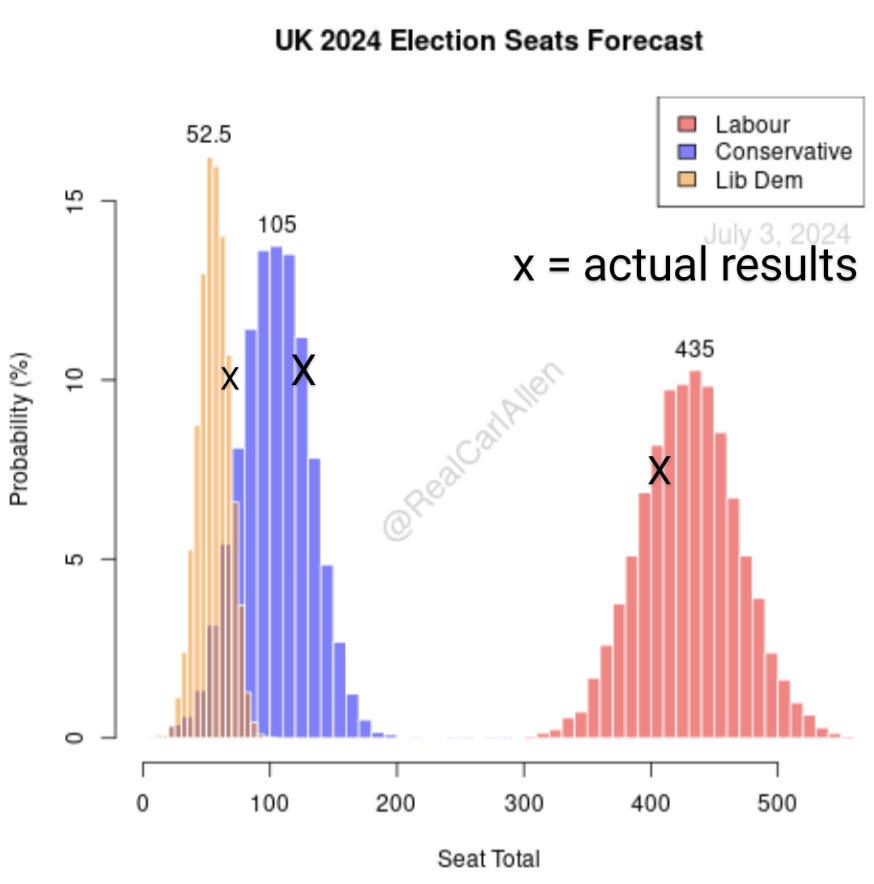
The Economist probably had the best forecast. You'll note it's not very different from mine, but I'm not mainstream enough to count.
What makes a good forecast, anyway?
As readers of my work know, probability isn't always easy. But it's not too hard, either - it just requires a small step or two past what our mind assumes.
Our brains are wired for binary thinking: black and white, yes or no, good or bad, right or wrong.
But like real life, probability is rarely that simple.
Our minds - and the work of very bad analysts - interpret these things as “calls” and tell the public they should too.
Worse, forecasts at least *try* to provide a win probability.
Polls do not.
And yet, allegedly reputable companies publish stuff like this:
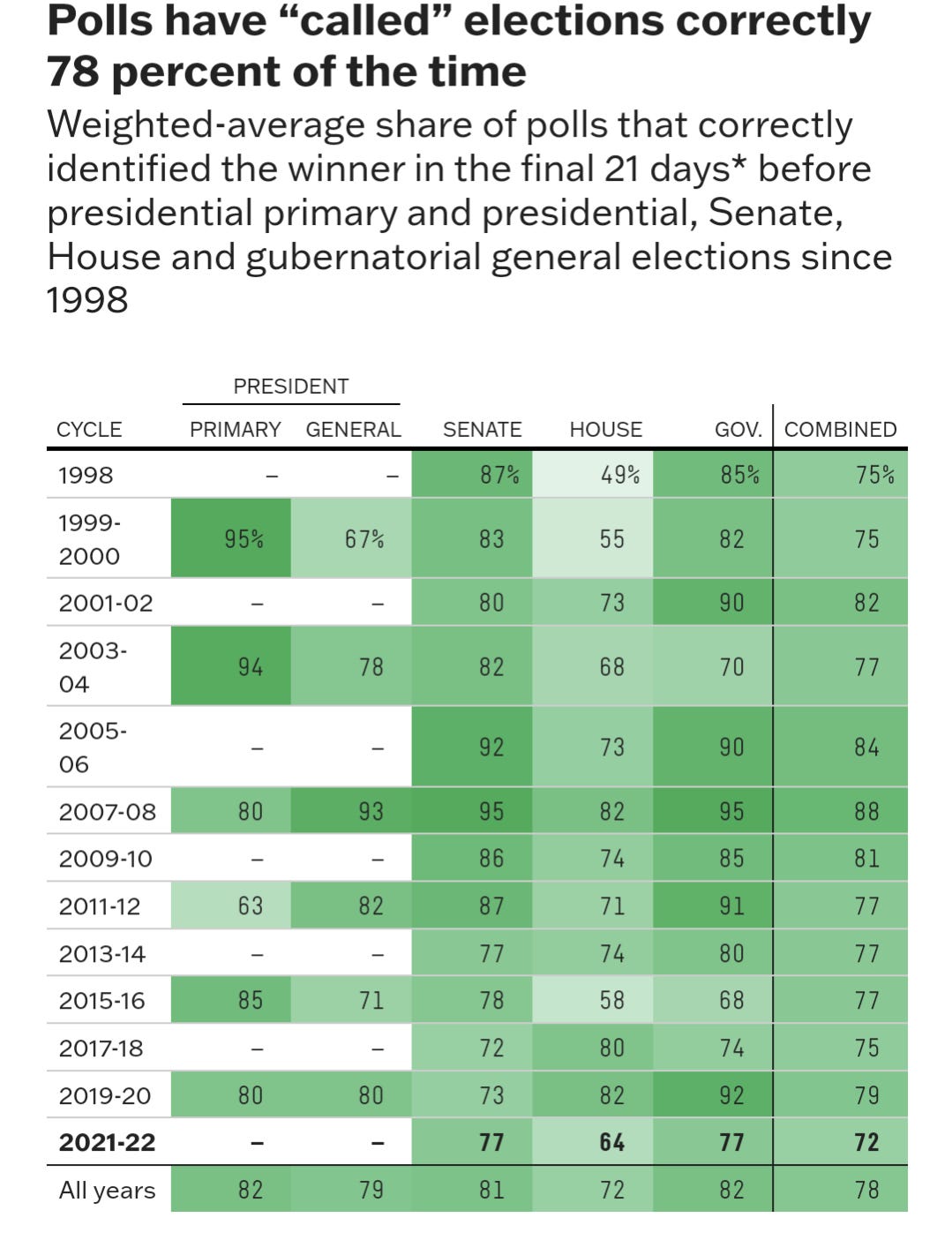
This is garbage and FiveThirtyEight should be ashamed.
That's not right.
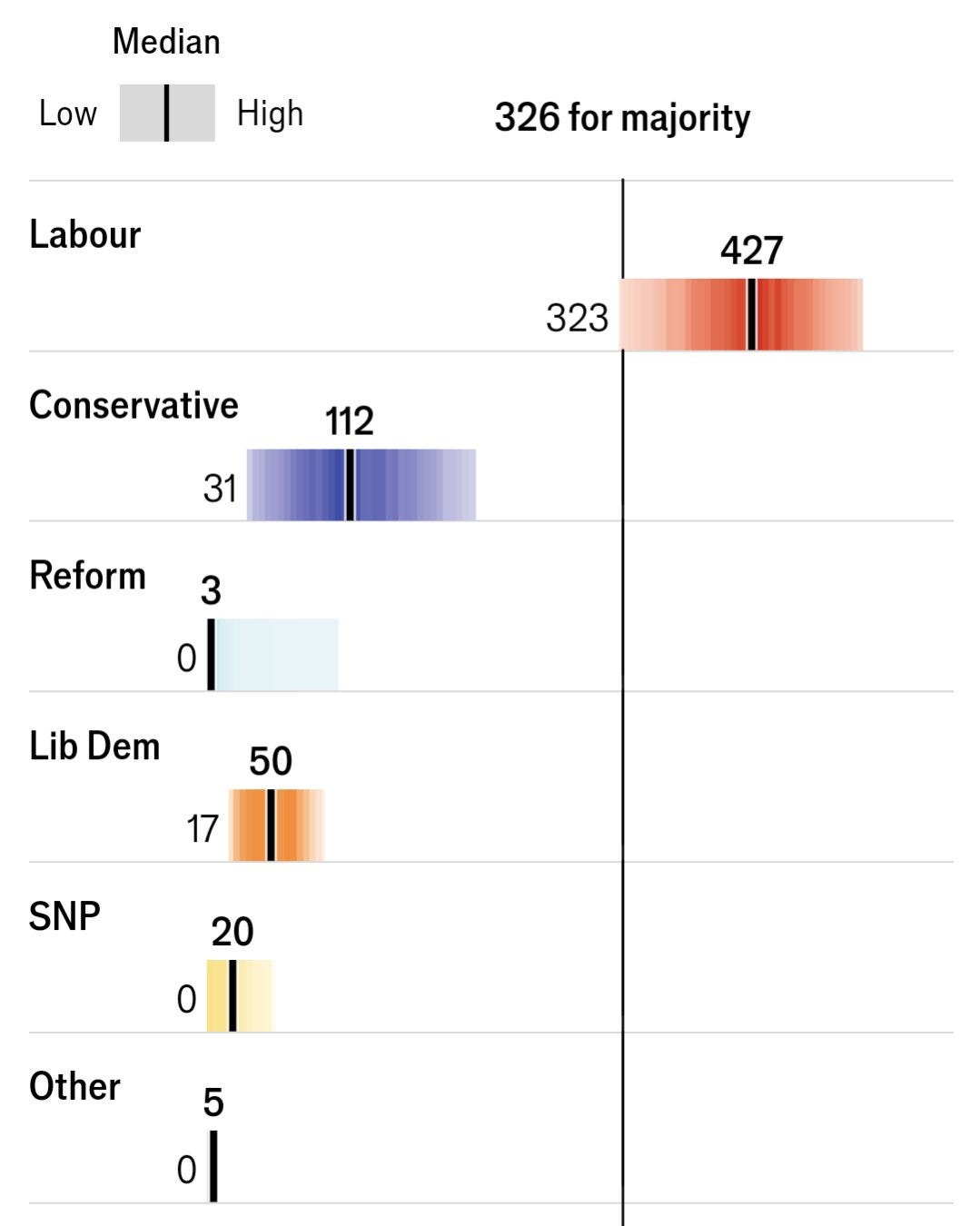
As for the UK Election forecasts:
You were probably drawn to the medians posted in the respective forecasts above, and it's really hard to get past the anchor of “close to median = good” and far from it means “bad.”
But I'm obligated to remind you, from a previous self-congratulatory article in which I had an excellent forecast in the London Mayoral Election:
It's just probability when my median is very close to the outcome!

To this point, it's pretty hard for many math and non-math people to wrap their mind around this concept. So I use one of my favorite analogies to make it easy: dice.
Here are the probabilities of rolling any specific number with two dice:
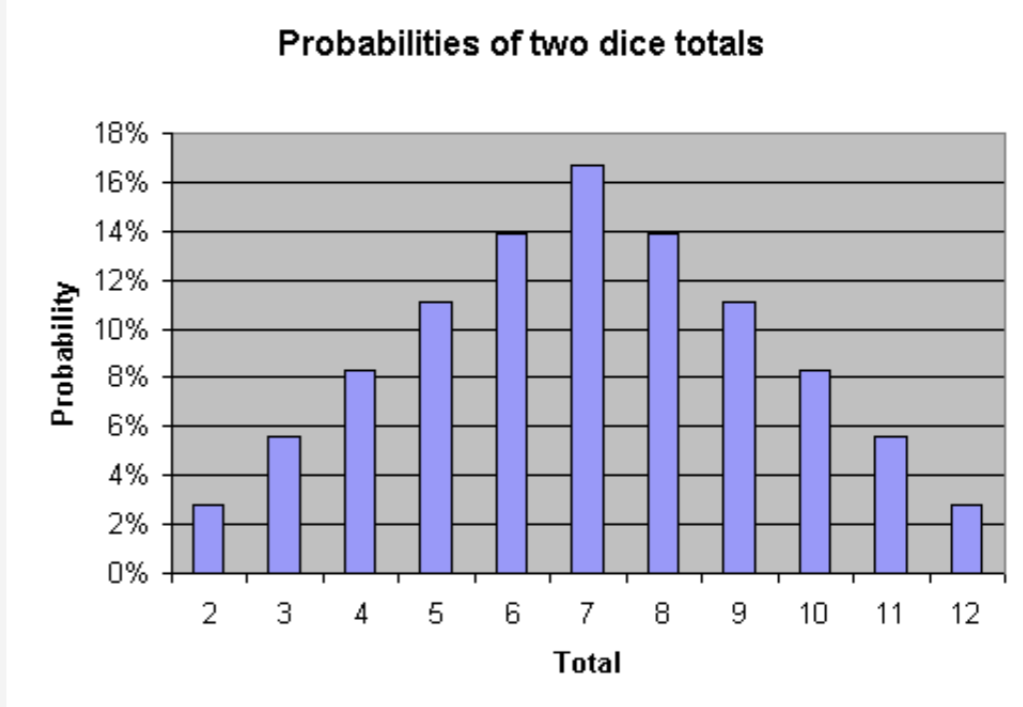
Now, the probability of rolling any specific number is low…and some are lower than others.
Simply put, even the most likely outcomes are very unlikely. This feels counterintuitive, how could the “most likely” thing(s) be unlikely?
But when we think about dice, it makes sense.
Now, my science brain starts working.
Why does this make sense but election forecasts are very poorly explained and understood, even among experts?
It makes sense because with dice, we can do the math pretty easily.
So, when I say the roll of two dice will result in:
7 +/- 4, with 95% confidence
You shouldn't give me “credit” if the roll is 7. I only said it had a 17% chance!
You shouldn't give me credit if it's “6” or “8” because I was only “off by 1”
All I did was say they each had a 14% chance.
In fact, you can do the math:
14% roll a 6
17% roll a 7
14% roll a 8
14% + 17% + 14% = 45%
Not only did my forecast not predict 7…
It literally said there's a greater than 50% chance my median is off by more than 1!
With dice, the correct median and 95% confidence intervals can be known objectively, with certainty.
And (selfishly or ignorantly) we want other, much more complex math to be so simple: we assume that because there is an answer (in some abstract, soothsaying sense) that someone must be able to find it.
But they can't.
It's a very flawed perspective (a textbook case of hindsight bias) to assume that what happened should have been the median expectation. This is precisely, literally, how poll accuracy is presently judged - and it's plainly bad science.
Smart people tell me this is a big part of the difference between Frequentist and Bayesian probability perspectives. That's true, but you don't need to be a practitioner of either to understand the basics.
That is to say, using the dice analogy (where medians and confidence can be known) and elections (where we don't and can't) are very different.
But I love to start with “knowable and known” to demonstrate how wide our range has to be to reach 95% confidence.
It's not impressive if you say rolling a 6, 7, or 8 has a 100% chance. Nor are you “right” if the roll results in a 6, 7, or 8 - and the dice are never rolled again. You were lucky.
Undue confidence is often rewarded disproportionately (and makes for much nicer headlines).

Totally over! Calling it!
Hack.
When we deal with the unknowable and unknown, like in election forecasting, practicing on a case where the median and probabilities are known, you see why we must allow for even more possibility of imprecision.
The more confidence someone has that they know some specific outcome, the more certain you can be that they're bad at math, lying to you, or both.
The most recent midterm election was no exception. More hacks showed their true colors in 2022, with Christopher Bouzy joining Sam Wang.
Though he didn't reach the level of “mainstream” fame Wang did, he has a carefully managed online persona which - I later found - is cultivated by simply blocking anyone who Dares Question Him (capitalization a reflection of his self image).

Here, the hack actually caught the attention of people who are good at math, and responded much more kindly than me. Basically, “lol no.”

Democrats ended with 213 seats.
You'll note, reader, that 219 was not Bouzy’s median. Nor did he offer any other language to suggest uncertainty.
Simply put, he assigned a 100% probability to “219” and he was wrong.
He wasn't just wrong because Democrats didn't end with exactly 219, in the godawful scenario I have to deal with hacks who get lucky, he was wrong because 100% is not a reasonable probability here. Pretending you know something just doesn't impress me. And it shouldn't impress you either. You should pity people like that, honestly.
Maybe it's for clicks, maybe he's actually that bad at math, but the “bad at math or lying to you” quote holds true.
He did the same for the Senate.
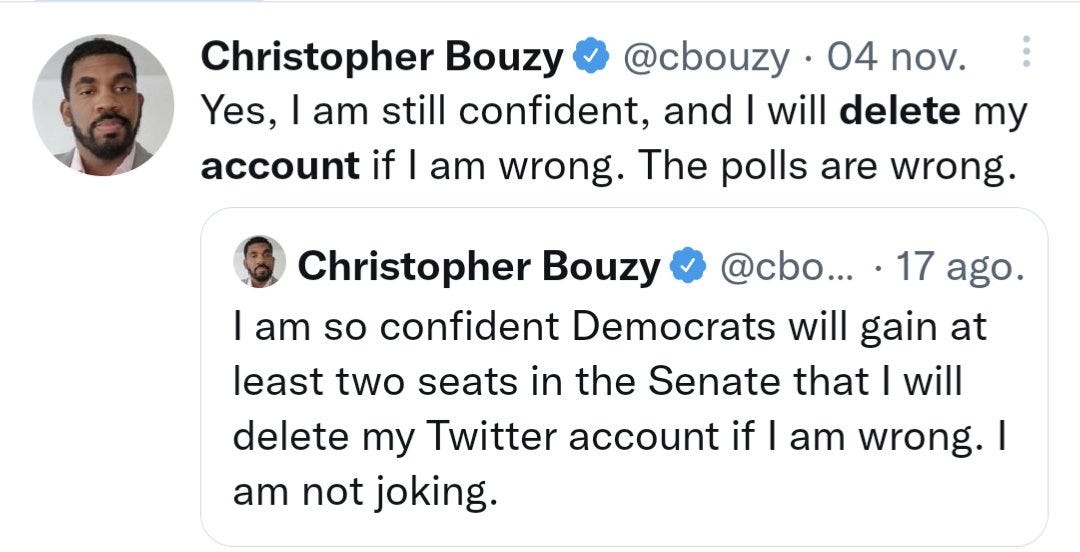
Upped the stakes this time. Wang said he'd eat a bug if he was wrong (and, as a man of his word, a small consolation, did so).
Democrats gaining “at least two seats in the Senate” would have required them to get 52 or more seats.
They got 51.
Bouzy, to date, has not deleted his account.
Now, many of his (cultivated) following argue - ah! But he was close! Closer than, like, all the others!
Well, for one, he wasn't closer than me but (resisting the temptation to sink to using bad math on people who use bad math)
He wasn't closer than literally anyone.
He assigned a 100% probability that Democrats would end with 52+ seats in the Senate. Even if they had, his forecast would have still been terrible (see the example of assigning a roll of 6, 7, or 8 a 100% probability above) but thankfully the statistical illiterate was wrong and his guess being incorrect allows us to not see him propped up by mainstream outlets for an election cycle.
The only prediction I'll make with a very high level of confidence - one day, some hack will make a good guess. They'll be very confident in their guess, their guess will be right, and their future guesses will be given lots of attention (until they inevitably Wang, Bouzy, or Literary Digest themselves). Don't fall for it.
What do the notes about Wang and Bouzy have to do with the UK General Election?
Well …
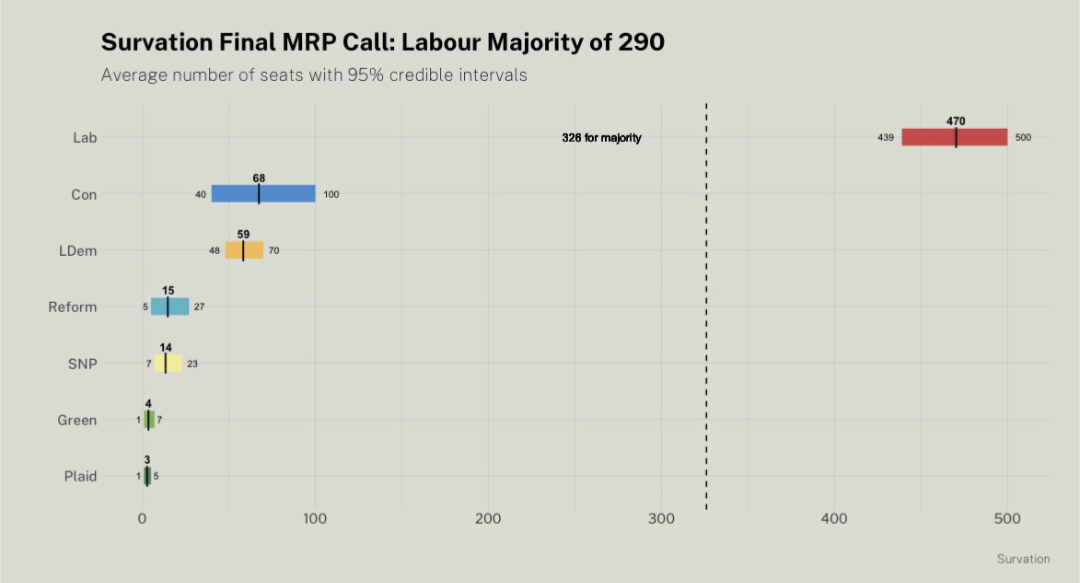
Here, we have someone much more reputable than Bouzy - a bonafide pollster who is a member of the British Polling Council (a rightfully respected organization) publishing a very, very bad forecast.
It's natural for your eyes to be drawn to the median, and noticing how far off the medians were from the result. That's fine.
My median was very far from most of theirs, so obviously we had some disagreement.
But I'm not immune to the possibility that my medians are bad, either.
The problem is how confident they were in their “95%” interval.
Here's what I said in advance of the election:
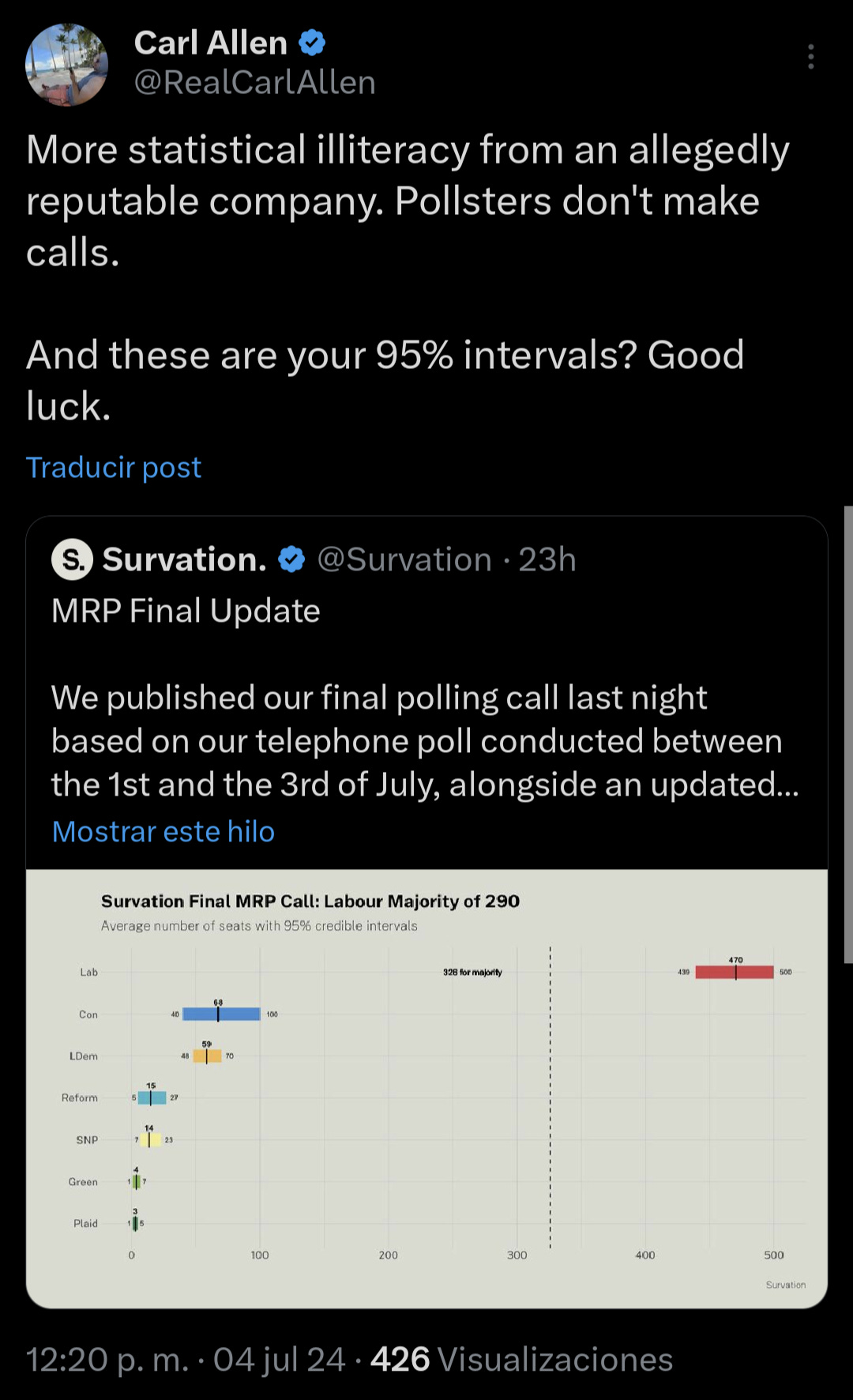
Plot twist: they blocked me for this.
I know I'm mean sometimes, but to borrow a quote from a friend:
If you can't tell by my love for dice analogies, writing a book related to poll data and statistical literacy, and that I teach English to non-native adults in my free time: I love teaching.
I love teaching because I love learning.
I am not mean to people because I am mean. I'm mean to people who refuse to accept the possibility that they are wrong, but simultaneously demand that they be taken seriously.
If any adult student argued with me about the improper use of a pronoun as fervently as these alleged experts argue about their use of junk science, I'd probably be mean to them, too.
And not because “I'm the expert, I know more than you, so you must accept everything I say as Truth…”
But because, in some specific cases, I'm right.
A more appropriate quote would be: “if you can't stand the heat…don't make a forecast. Or make a better forecast.”
I will be wrong about something, eventually. And I've been wrong before. It's fine. But not learning from our mistakes is really bad science!
I have accepted the fact that I could be wrong about something - or anything - I assert as true, in this field. And I'm fine with it. I'm not sure many experts have conceded the same.
The reason the Survation forecast was bad, was because it was overly confident. As overly confident forecasts often do, they missed.
While it was clearly much more scientific than Bouzy and Wang, it was still bad, inside their confidence interval or not.
And they were outside of their assigned 95% interval for each of the top 3 parties.
Regardless of median, their forecast was bad.
7 +/- 2, when you're rolling two dice, is a bad forecast if you want to be 95% confident, even with a perfect median.
8 +/- 4, while the median is objectively bad, would still very good, given how hard election forecasting is.
Even 9 +/- 4 (if you ignore that it overlaps an impossible outcome) wouldn't be worth raising a fuss about either.
But, say, 9 +/- 2 (more analogous to where I think their forecast was) is very, very bad.
This isn't an aberration, this is a pattern.
It happened in the Mayoral Elections, too.
One forecaster saw every election they forecasted produce a result outside their stated margin of error.
And one analyst graded them as “middle of the pack” for accuracy.
Coincidentally, or maybe just ironically, the “highest rated” pollster from the Mayoral Elections…just a few weeks ago…Survation.
It's almost like grading pollsters on their closeness to median is junk science.
The problem, in the UK, pollsters are asked to be forecasters - and they honest to God do not know the difference between poll data and forecast data. They report it as the same thing.
For reasons you probably understand, being a good pollster (collecting reliable data) and being a good forecaster (figuring out what the data means, plus lots of other inputs, and applying appropriate levels of confidence) are different skills. More different than they seem.
Fortunately, one thing we have going for us in the US, pollsters at least report their data honestly - even if they use pseudoscientific “spread” metrics in their reporting.
But for the foreseeable future, I'm done with foreign elections, I'm done with my book (please follow the link and add to your Wish List to preorder in September!)
And it's time to share some US data.
The markets don't seem to think Biden will be the nominee…but I do. And despite his age being a clear negative, I still think that's a good move overall.
My forecasts will be shared here soon.