

Maryland Senate Primary

I have written about the dangers, and folly, of viewing polls as predictions for years.
People smarter and nicer than me did so decades before.
The methods used for analyzing poll accuracy continuously, provably, and predictably fail, and the people who dare to call themselves experts continue to mislead and misinform the public.
I'm not going to rehash all of the underlying reasoning as to why polls aren't predictions.
You can read more here, here, here, here, here, roughly every day on my social media, or when my book comes out, in more depth.
The shortest way I can put it is this:
Polls attempt to estimate the current state of an unchanging population, not the future state of a changing one. It is literally the foundation upon which poll math was derived and is still used to calculate a poll's margin of error today.
The generalization of survey data being limited to THE SAME POPULATION is 101-level stuff, and most experts fail it.
Polls have undecideds, elections don't. Polls and elections are, literally, different populations who are being asked different questions. (No, “who do you plan to vote for” in a poll is not the same as “who did you vote for” as measured by an election, because those questions have different options)
There's nothing wrong with using polls to INFORM forecasts, because being able to estimate the current population (poll data) is the best possible information we can have to estimate the future population (forecasts).
The analogy I love to use is body weight. My body weight today, as measured by a scale, is the best possible data I can have to inform a prediction of my weight tomorrow, next week, or next year. But it is not a prediction of it!
Scales, too, are subject to error. But because you know how scales are intended to work, you wouldn't compare a scale's reading of your weight today to one tomorrow or next week, and assume the entirety of the discrepancy must be a scale error.
This is literally the unscientific and, sorry, ignorant standard by which polls are presently judged - and have been for a century.
Can you think of any confounding variables between today's weight measurement and next week's, that need to be controlled for, before calling the discrepancy between “present weight” and “future weight” the poll's…err…scale’s error?
Properly read, polls are not as accurate as scales, but they are remarkably accurate. Like, way more accurate than I, you, or anyone would have ever imagined (teaser).
But polls and forecasts are TOTALLY DISTINCT ENTITIES.
The fact that polls can be predictive does not make them a predictive tool. This is a simple enough concept I acquired analyzing sports data, and I hope it makes sense.
And if it doesn't, I'll step on a scale and ask you to predict what my weight will be next week, to illustrate.
The status quo says the accuracy of poll data can be measured by how well that tool (which is not intended to be predictive) predicts the outcome.
It is objectively, mathematically false, and it's a disgrace that it is allowed to continue.

Polls, or poll averages, do not attempt to measure (or estimate) a future state.
They attempt to measure a present state, sometimes, rightfully, analogously called a “snapshot.”
If your prediction - informed by the snapshot - is wrong, does that mean the snapshot was?
In elections, the present state in question often includes a lot of undecided voters.
In the absence of this understanding (or application of it) the election result has been substituted for the “present state.”
The election result IS NOT a present state “snapshot” - which is the objective standard polls attempt to measure - but a future state.
Like diet, exercise, hydration status, and even illness are possible confounders to your weight change over time, the flawed standard in poll accuracy measurement introduces at least two major confounding variables:
Changing Attitudes (people can change their mind between when the poll was taken, and the election, for any reason or for no reason. The current methods assume that this must be zero, inside of an arbitrary three week window they made up, despite it being provably false).
Undecided Ratio (undecideds do not always split in a predictable or consistent manner. This alone gets a chapter or two of analysis in my book, because it's more complex than it sounds, but suffice it to say US analysts assume undecideds must split 50-50 between the major candidates, or the poll was wrong. Even when there is strong evidence to suggest this is not the case, analysts do not fix their assertion of poll error. Non-US analysts make a different default assumption about undecideds, because apparently math is different depending on where you live. This also gets a chapter.)
My approach for analyzing poll accuracy, which is a valid one by scientific standards, adjusts for confounding variables.
Good science, unfortunately, is a little harder than pseudoscience.
I understand that polls only attempt to measure a current state, you (if not before reading this) also understand it. Roper understood it 80 years ago:
“We learned that the press is not ready to handle the survey tool properly...our problem is to get the press to accept polls as analytical and speculative, not as predictive tools”
Sound eerily familiar?
And Panagakis understood it 40 years ago:
“Many polls remembered as wrong were, in fact, right.”
Both of these men, indisputably experts in the field, had a level of understanding that I believe was higher than their peers.
So where did it go?
It was drowned out by junk science and “margin” analysis that…treated polls as predictive. And the field has suffered for it.

I do not believe that I am as smart as Roper or Panagakis (nor Silver or many others, frankly) and I don't have the credentials they do - but I do have a couple major advantages over them:
I'm not as smart as them, and I don't have the credentials they do.
I joke, but it's kind of true. When you work within a field (and your income relies on people hiring you, liking you, and receiving advancement opportunities) you're far less willing to rattle cages that challenge the status quo, even if you do understand things need changed.
True, I am way too mean sometimes and I'm trying to work on my tone - I used the word folly in the intro!
But the reality is, the existing standards are wrong, and I believe a scientific field should adhere to scientific standards, which includes adjusting for known confounders.
Where I believe I have an actual advantage over those who came before me in the field, and those currently working in it, is that I will not assume smart people understand something when their words prove otherwise.
I'm often told “experts understand polls aren't predictions…even if their analysis betrays that.”
No, they don't. (Or, no them don't).
In an attempt to explain things, where experts have failed, I have named the objective standard that a poll attempts to measure a “simultaneous census.”
Copy-pasting from my last article.
What does poll data attempt to tell us? It's an estimate of a simultaneous census. If an ideal poll is taken simultaneously from a population, a true census that asks that same population the same question, will produce a result within the margin of error as often as your confidence interval specifies.
That's it. Nothing to do with the eventual result.
If you want to contend that political polls “can't be ideal” or that a “simultaneous census is impossible” in political polling applications, I would mostly not contend it, because it literally does not matter. Your feelings about what is or isn't possible doesn't govern math.
All of these concepts are easily testable, and replicable, as good science is, if for some reason it is controversial.
Oh yeah, Maryland
With the understanding that polls are NOT predictions, but estimates of a simultaneous census, here is a glimpse of what those scientific standards should look like.
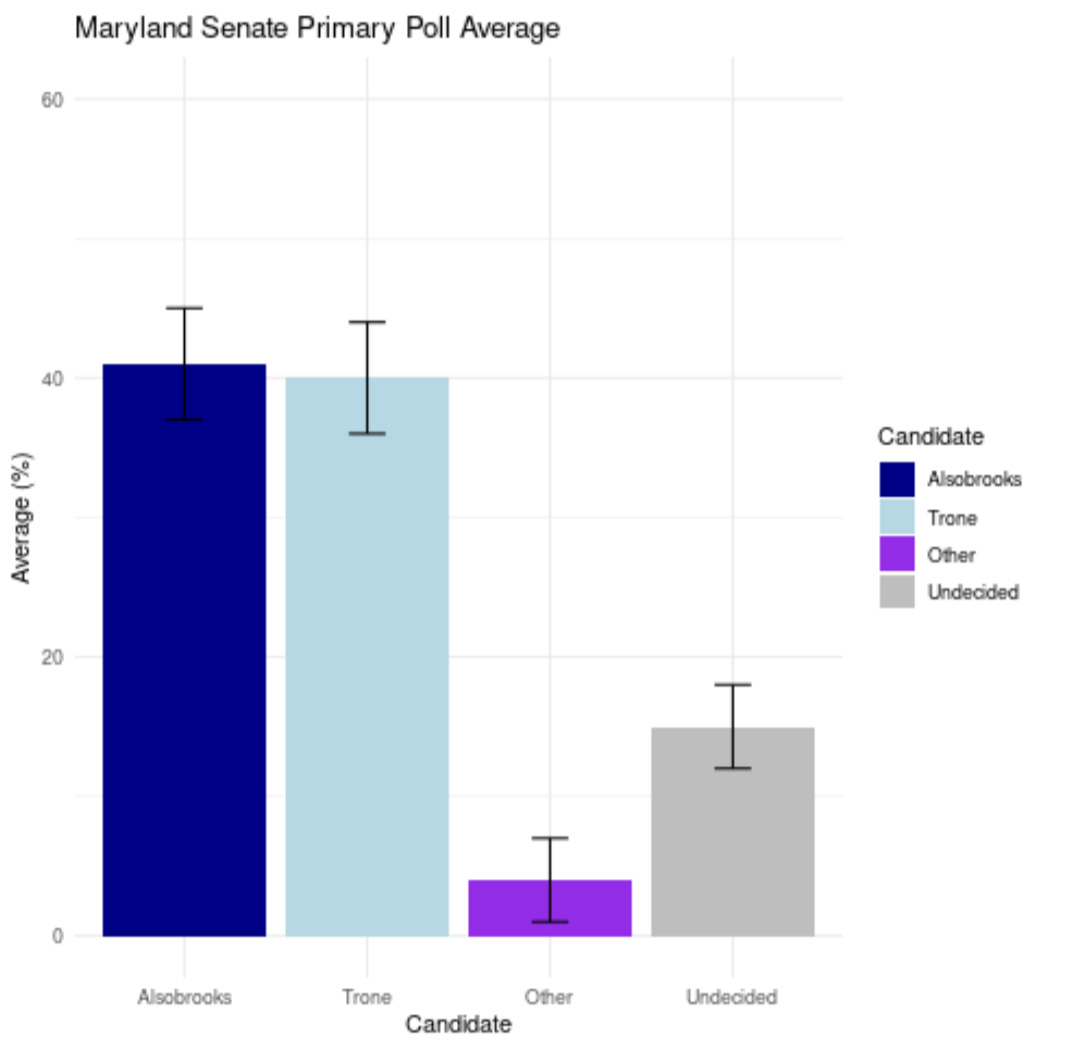
The margin of error given by a poll (or poll average) is not a prediction.
It is an estimate of the simultaneous census.
The margin of error given by a poll applies to the number of undecideds, too - because undecided is an option in the poll, and some people chose it.
That's how inferential statistics work.
You, or a model that makes various assumptions (informed or otherwise) can make any number of assertions of what you believe undecideds will/should/might do: nothing to do with the poll.
Likewise, you can assume how many people will change their minds. Nothing to do with the poll’s accuracy.
The error of this poll average is not - as is wrongly reported by alleged experts - measurable, or even approximateable by any scientific standard - solely to the election result.
It can only be compared to how close this was to the population when the average was taken. Undecideds and all. Period.
End of poll analysis.
The election is not an objective standard for measuring poll accuracy. It is an objective standard for measuring forecast accuracy.
The election is a near-simultaneous near-census from which we can work backwards (accounting for known confounders) if we wish to better calculate poll accuracy. I do that in my book, and that's the direction this field's analysts need to go.
More directly (and easier to explain) the accuracy of individual polls can only - in a scientifically valid way - be measured against this simultaneous census standard as well.
For example:

Emerson took a random sample of 462 Likely Voters.
If they had taken a simultaneous census of all of the state’s likely voters (asking the same questions, at the same time, to the same population), how closely would it have been to their poll?
That's the only proper standard to measure poll accuracy.
I know that sounds hard and theoretical, because it's not possible in political polls.
But it's true.
It's a concept that is testable and knowable on smaller populations, where a simultaneous census IS possible, and demonstrates some important points (again, sorry, book).
And only once you understand what is true, even if you can't know the truth with “moral certainty,” can you develop better methods to approximate it. That's the entire point of poll data! That's the exact foundation the statistics provided us.
Then, enter those confounding variables I mentioned earlier.
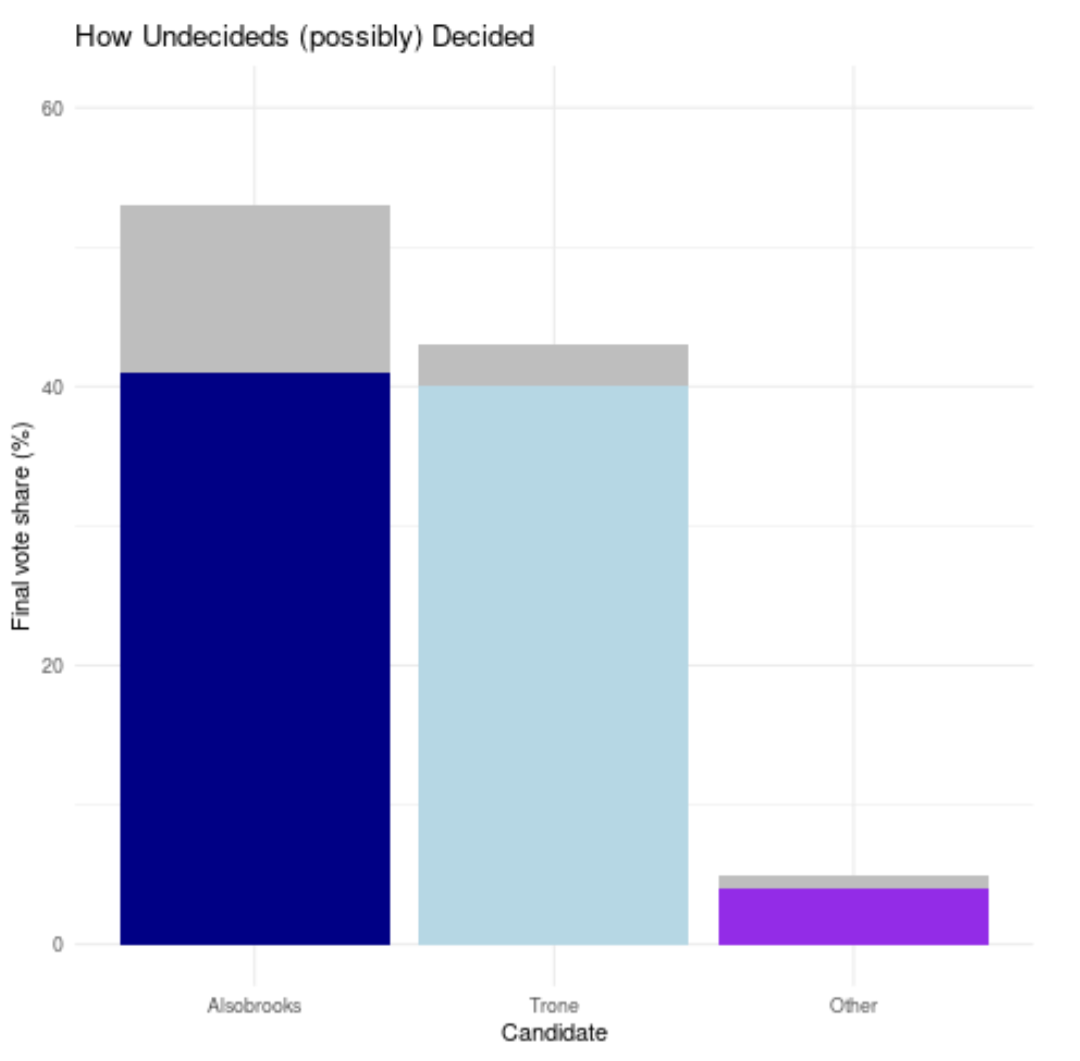
With Alsobrooks finishing at 54%, she clearly outperformed her poll numbers, and poll average, by a lot.
So, as a respectable scientist or researcher, here's the question:
Where did those votes come from?
It's a somewhat complex (but not too complex) problem to answer.
The shortest answer is:
If most of the people who declared they were undecided in the polls eventually voted for her, there was likely very little, if any, poll error - properly defined.
If the polls dramatically understated her simultaneous census value, it's fair to call it a poll error.
So which is it? Possibly in between? No one knows. The unscientific standards in this field substitute guesses for data and have the audacity to call it math.
Here's a visual of what the “silver” undecided distributing from the poll average, compared to the final result, would have looked in a “zero poll error” scenario.
In some of my posts, I may come across a little conceited. I'm not, really, but I understand why some of what and how I write can be taken that way. It's okay.
But my most arrogant persona could never, ever, approach the gargantuan ego that is the US “experts” in this field, who ASSUME (based on no data) that undecided voters MUST split 50/50 in every single election, or the polls were wrong. (Other country's experts are, somehow, even worse).
It's indefensible. Even when presented with evidence it didn't happen, they still attribute the entirety of THEIR ASSUMPTION ERROR onto the polls.
As someone who has a respect for science and the scientific method, it's disgusting. If my tone is harsh, or harsher than you feel it should be, this is why.
Sorry, something you assume should happen not happening isn't a poll error.
Good researchers would, before making ANY assertions of error, account for those confounding variables of mind-changing and undecided splits.
But currently, “polls was wrong” seems to be sufficient. It gets clicks, which gets them paid, so even if they do understand why it's wrong (which most don't) it's not a strong enough motivator to fix things.
But good data is boring. It takes time, money, and lots of time. In the weeks it takes to collect that good data, people have already made up their minds about how accurate the polls were (no more clicks left for you) thus, the incentive to produce good data is small.
Fortunately, there have been some researchers to do it, which effectively proves my point. Do not look at this chart.
Do not look at it.
Undecideds split evenly and no one changes their mind.
Don't look at it.
Don’t.
Undecideds split evenly and no one changes their mind.
Of course, a proper scientific field would not place assumptions where data could go.
But here we are.
The FIRST step in calculating poll error is:
How many people changed their minds since the poll?
How did undecideds eventually decide since the poll?
Subtracting numbers from other numbers and assuming your assumptions can't be wrong isn't science. It's not even good math.
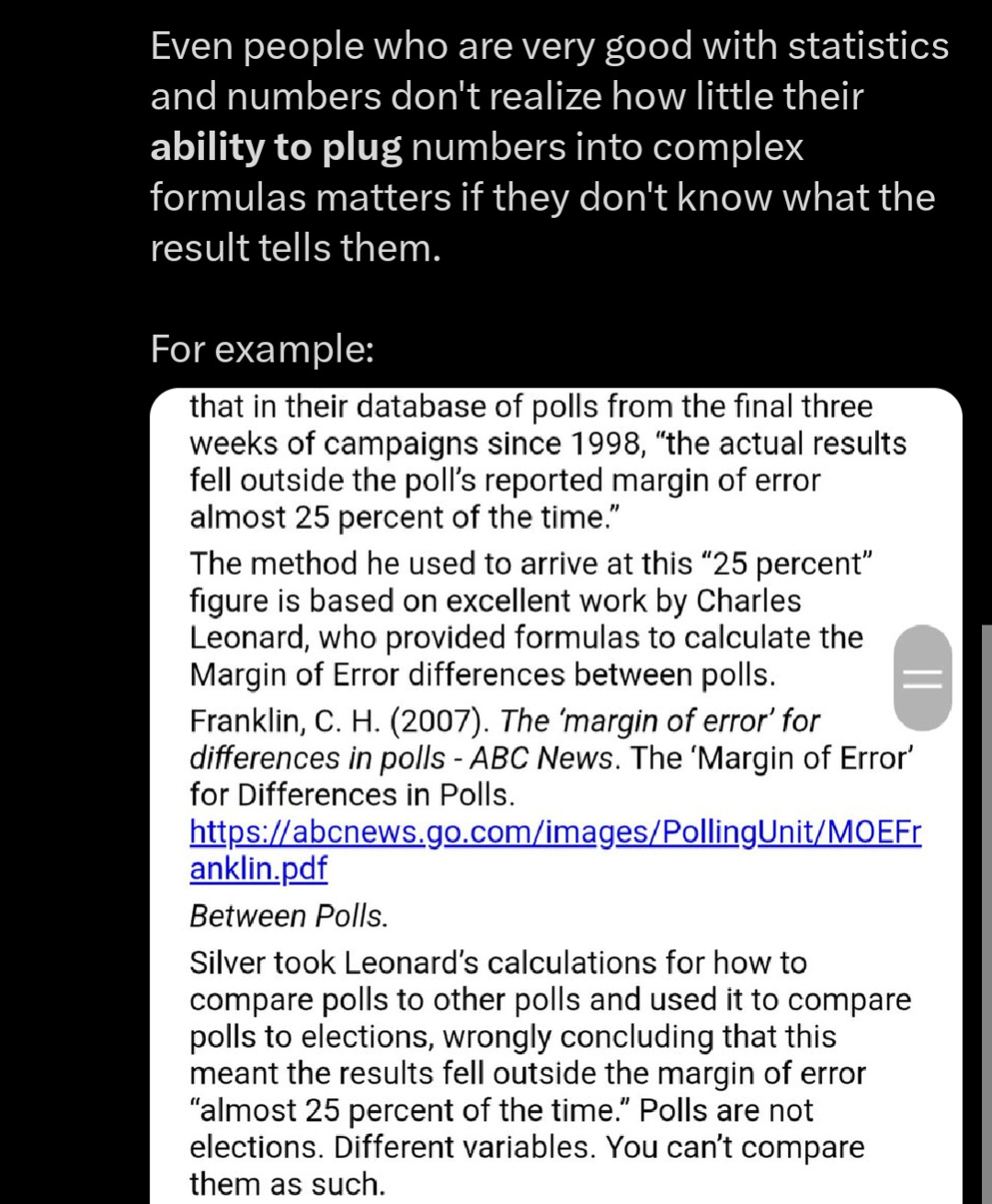
There are precedents for properly calculating poll error (even if they didn't conduct the study with that in mind) but it requires understanding a couple simple confounding variables.
This is not to say polls CAN'T be wrong.
If there were data to suggest undecideds split evenly, or that they only split 60-40 for Alsobrooks, that's strong evidence.
But assuming your assumptions can't be wrong is not evidence, it's ignorance, by definition.
Elections with a high number of undecideds are more susceptible to unexpected outcomes, if you make the mistake of only looking at the “spread” or “margin” (which is something experts tell you to do).
Nick Panagakis - quote highlighted below - brilliantly summarized this mistake as “rules of analysis are necessary.”
That one candidate is more likely to outperform their poll average by 10% when there are 15% undecided, than when there are only 5% undecided, is a statement I feel is so boringly obvious I'm embarrassed to make you read it.
Yes, a poll or poll average of 43-42 with 15% undecided is far more likely to see a result where one candidate wins by a lot than a poll or poll average of 48-47 with 5% undecided, despite the same “spread” of +1.
But because of how broken and unscientific this field is, that objective truth qualifies as groundbreaking knowledge. Despite the fact that we've had it for (at least) 40 years, and it came from experts - not random nobodies like me.

But this understanding, combined with the fact that polls do not attempt to predict how undecideds will eventually decide, literally makes you more knowledgeable about poll data than the majority of experts.
There are many more moving parts to poll error calculations which are - again - not too complex for the average poll consumer, but you have to understand the difference between poll error and assumption error first. I go into more depth in the book.
Hope that makes sense.
Please leave a comment and share if you liked this article.
I've been thinking about what you said yesterday. I still don't think they're lying. They just may not be nearly as smart as you think, and you may be a lot smarter than you realize.
I'm not sure they understand your argument. They're not trained scientists or mathematicians. They can be sloppy thinkers. When I was in grad school, I had faculty challenge me, question me, and criticize me. They're not used to having basic assumptions questioned. I am. They have a lot of "yes" people around them who can't tell them, 'look, you say you're not predicting, but you just used the word, "prediction," anyway'.
Honestly, if they can't see what you're saying, then there's something wrong. You're right that this is pseudo-science. That's accurate.
Your point about the advantage of your not being part of the polling data club is right. They have to be careful about what they say because they can lose colleagues if they challenge certain assumptions. You don't have that issue. That points to the danger of not listening to those outside one's circle. We all need to get out of our limited circles periodically.